TL;RD
- Among the myriad tasks you can request a GPT model to perform, scraping or parsing will be one of the most attractive to localization engineers since you can build glossaries and translation memories out of related multilingual files.
- Most GPT models won’t let you scrape websites, but you can circumvent this sane limitation using a markdown clipper. Advanced Python users can use BeautifulSoup.
- Few-shot prompting will help the model extract the desired information. Also, make sure to add rules to reduce the chance of hallucinations.
- Perplexity.ai (affiliate link) includes Claude 2 among its available GPT models. Their UI is extremely easy to use, and subscription starts at $20/month.
The importance of building glossaries or termbases in localization
In localization operations, glossaries or termbases help keep consistency across the board.
Also, they increase translators productivity because they don’t need to send many terminology queries or research online for potential candidates.
When onboarding a new client (LSP) or a new product or service (buyer), you will likely need to compile key terminology present in the documentation to be localized.
In this blog post, I will show you a way to compile this terminology using Claude 2.
The context of the experiment is as follows:
- A client comes with a new marketing campaign
- It is about a new flagship phone
- They have launched in Spain and now will do it in Latin America
- They want to keep the same terminology for technical specs
- They have two dedicated landing pages about the product: English (EN-US) and Spain (ES-ES).
I am going to use the new iPhone 15 Pro as the guinea pig.
Step 1: Scrape the text from landing pages
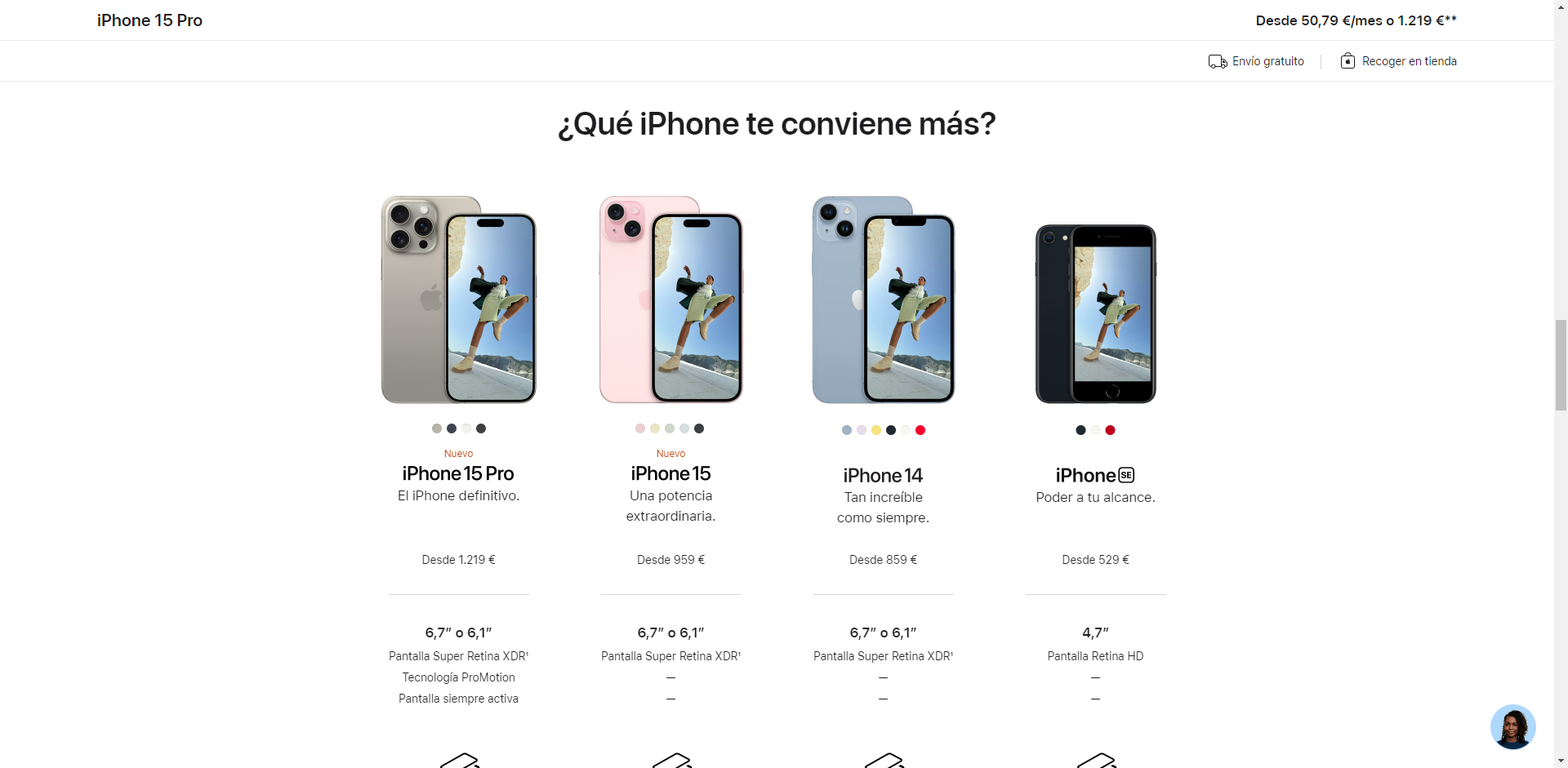
We have one source of information for our bilingual glossary – the landing pages.
They live on a server, so a way to access them is via an HTTPS request. However, GPT models do not proceed to do such requests for scraping purposes.
There’s also the HTML way, but the model may have a hard time juggling across classes, elements, attributes, etc.
What options do we have? Well, MarkDownload comes to mind.
MarkDownload is a Chrome extension that takes the HTML of an active page in your browser and translates it in markdown format, stripping anything that it’s not text.
For instance, <h1>Building glossaries<h1> becomes #Building glossaries.
We will save a TXT version of each landing page in our local drive.
Why not MD? You may ask.
I couldn’t make Claude 2, GPT-4, or Perplexity’s custom GPT model to read markdown files in my particular case. For some reason, GPT models have become a bit lazy.
Step 2: Write a prompt for glossary building
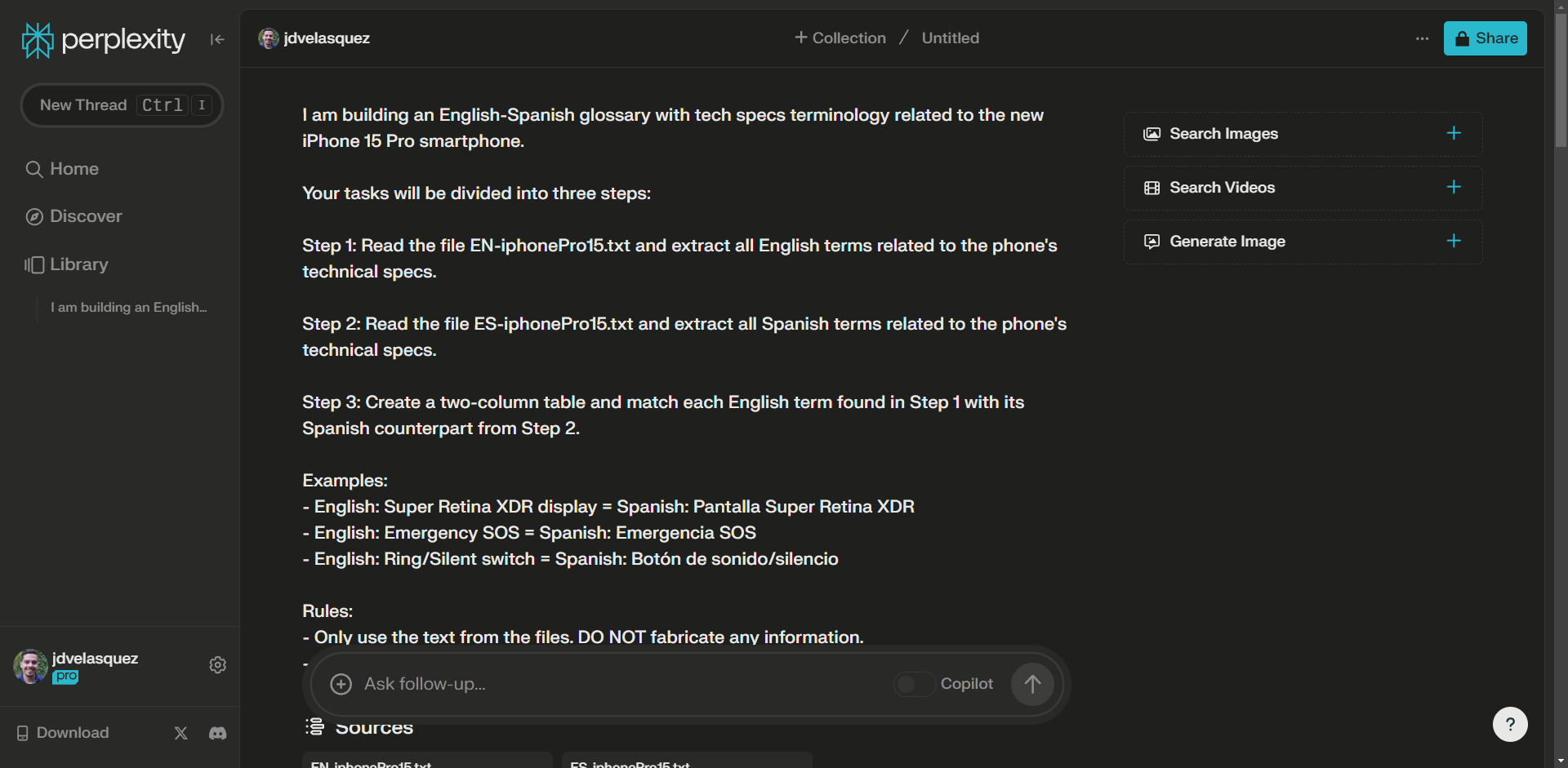
My go-to GPT environment is Perplexity. It was one of the first platforms I used upon GPT-3 release. I love the fact that I can choose between at least three different models.
One of the models is Claude 2, which supports file uploads, meaning that we can have our model interact with them.
Additionally, I chose this one because it was the only model that perfectly followed my prompt and didn’t fabricate any information.
Here is the prompt I used:
I am building an English-Spanish glossary with tech specs terminology related to the new iPhone 15 Pro smartphone.
Your tasks will be divided into three steps:
Step 1: Read the file EN-iphonePro15.txt and extract all English terms related to the phone’s technical specs.
Step 2: Read the file ES-iphonePro15.txt and extract all Spanish terms related to the phone’s technical specs.
Step 3: Create a two-column table and match each English term found in step 1 with their Spanish counterpart from step 2.
Examples:
- English: Super Retina XDR display = Spanish: Pantalla Super Retina XDR
- English: Emergency SOS = Spanish: Emergencia SOS
- English: Ring/Silent switch = Spanish: Botón de sonido/silencio
Rules:
- Only use the text from the files. DO NOT fabricate any information.
- Consider two- and three-word terms.
Let’s go ahead and process it in Perplexity.
Step 3: Review output and optimize
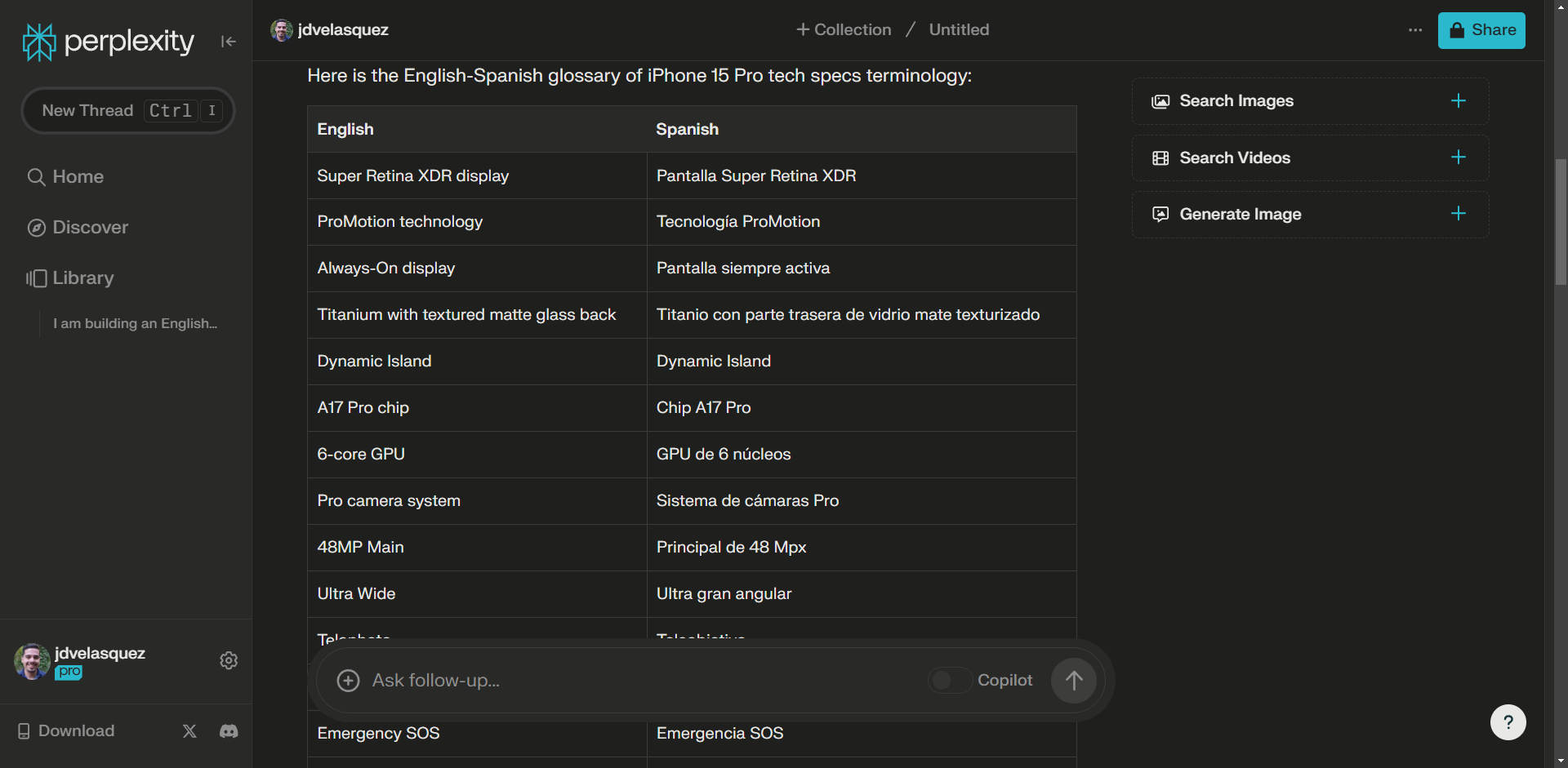
At first glance, it did a good job. It considered phrases with more than three words, but I am particularly happy with its choices.
Secondly, it focused on the specs section, which is exactly what I asked for.
Now that we know the process works—or at least for this case—one potential improvement to our prompt is to ask it to print the terms using the TBX schema.
We would need to replace Step 3 as follows:
Structure the resulting term pairs using the following TBX schema:
105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130<?xml version='1.0'?> <!DOCTYPE martif SYSTEM "TBXBasiccoreStructV02.dtd"> <martif type="TBX-Basic" xml:lang="en-US"> <martifHeader> <fileDesc> <sourceDesc> <p>This is a minimal TBX Basic sample file.</p> </sourceDesc> </fileDesc> <encodingDesc> <p type="XCSURI">TBXBasicXCSV02.xcs </p> </encodingDesc> </martifHeader> <text> <body> <termEntry id="1"> <langSet xml:lang="en-US"> <tig> <term>"english term"</term> </tig> <tig> <term>"spanish term"</term> </tig> </langSet> </termEntry>
This way, we can use an external utility to import our new terms into an existing glossary or termbase.
Why don’t you try it and tell me if it works?
Final thoughts on glossary building with LLMs
Although this proposed way of creating bilingual (or multilingual) glossaries has several manual steps in between, the results are promising.
You can also ask it to extract creative marketing phrases using the few-shot technique to help it focus on the desired texts. I tried it, and the error rate is thin.
Will the days of using complex/expensive software or frequency-based methods to extract terminology be forgotten?
Possibly. That’s my hope.
As a final word, please share this information with your favorite localization pal. You may be saving their day.
Конец.
Updates
12/15/2023 – GPT and scraping without the middlemen
Andrej Zito, one of my favorite localization people, mentioned in one of my LinkedIn posts that it would be unnecessary to scrape the websites using a separate tool like MarkDownload because most LLMs can perform this operation.
His claim is partially valid. GPT-4 can’t perform the scrape operation by itself. You need a third-party tool to do the job and then have GPT-4 to do the parsing.
You can scrape a website using a Python library, such as BeautifulSoup, Scrapy, or Selenium.
This blog post covers an extremely easy process for those who don’t want to go down the Python path.